OSD layout, redes separadas, pools y tuning básico
¿Qué problema resuelve Ceph aquí?
Un cluster de Proxmox sin almacenamiento compartido real tiene un límite claro: no podés hacer live migration de VMs con estado en disco. Necesitás que el storage esté disponible desde cualquier nodo.
Con 3 nodos, Ceph hiperconvergente es la opción natural — los mismos hosts que corren VMs también alojan los OSD, eliminando el SPOF de un storage centralizado.
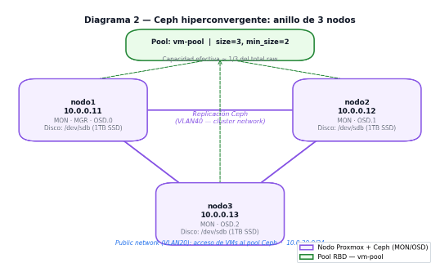
Figura 2 — Anillo Ceph de 3 nodos: MON, MGR y OSD distribuidos. Pool vm-pool con replica size=3
Arquitectura del anillo mínimo
- 1 MON (Monitor) por nodo — 3 MONs para quorum de Ceph
- 1 MGR (Manager) activo en nodo1 + standby automático
- 1 OSD por nodo mínimo — disco dedicado (/dev/sdb), separado del disco del SO
Con 3 nodos: size=3, min_size=2. Los datos se escriben en los 3 OSDs y el cluster tolera la pérdida de 1 nodo sin perder datos ni acceso de lectura/escritura.
Redes: public vs cluster
- Public network (VLAN20 — 10.0.20.0/24): tráfico de lectura/escritura desde VMs
- Cluster network (VLAN40 — 10.0.40.0/24): replicación interna entre OSDs — alta bandwidth, aislada
⚠️ Error común: Usar la misma red de Corosync (VLAN30) para la Ceph cluster network. La replicación de Ceph bajo carga afecta la latencia del quorum de Proxmox. Mantenerlas separadas es crítico.
Configuración paso a paso desde la UI
- Datacenter → Ceph → Install Ceph en cada nodo
- Configurar Public Network: 10.0.20.0/24 y Cluster Network: 10.0.40.0/24
- Crear MONs en cada nodo — mínimo 3
- Agregar OSDs: seleccionar /dev/sdb en cada nodo
- Crear Pool: nombre vm-pool, Size: 3, Min size: 2
- Agregar como storage: Datacenter → Storage → Add → RBD → apuntar al pool vm-pool
💡 Tip: SSD o NVMe para los OSDs hace una diferencia notable en latencia. Especialmente con VMs de base de datos o muchos IOPS simultáneos.
Verificación del estado
ceph -s — health, OSDs activos y utilización del pool
ceph osd tree — verifica que cada OSD esté bajo su host en el crush map
ceph df — uso actual de los pools
Estado saludable: HEALTH_OK con osd.0, osd.1, osd.2 todos up + in.